Quxlang development largely slowed down a bit… Not because I’ve given up, but because it got rather slow to compile and very hard to debug by searching through 15k lines of std::cout print messages. So I’ve been working on a solution which I call QueryGraph. It’s still a work in progress, but almost done enough to talk about its capabilities and how it works. Really, the main thing that is left to finish is the Debug GUI, most of the core runtime functionality is working already.
Before explaining what QueryGraph does, we can first examine the QueryGraph debugger. A picture here is worth a thousand words:
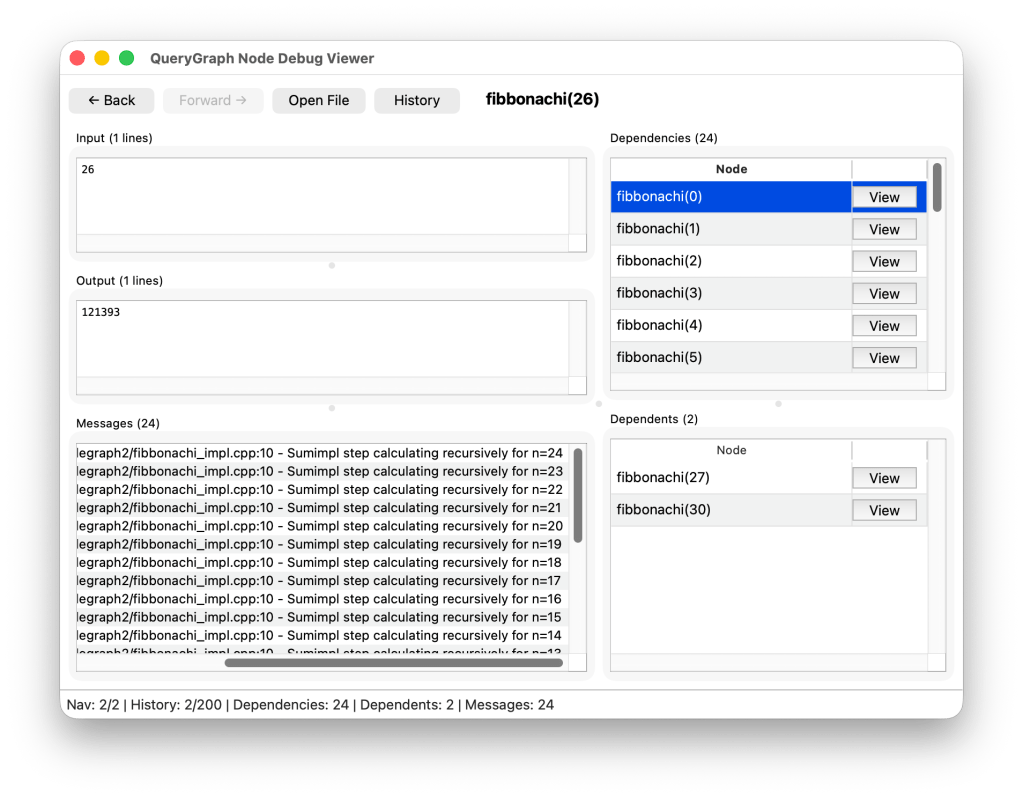
Okay, so the Node Debugger is a debugging UI for the internal graphs. Of course, in the real compiler implementation, I would not be using QueryGraph to find Fibbonachi numbers, but rather using it for nodes such as for example class_size(MODULE[main]::foo).
One of the bigger problems I encountered while working on the Quxlang compiler was… compiling. The existing resolver implementation has a big weakness, when any of the resolver input or output types is modified, or when a resolver is added or removed, this affects compiler.hpp or files included from it, which forces every resolver to recompile from scratch. I ended up spending quite a long time waiting for it to recompile in general. And compile times were only getting worse exponentially as more node types were added.
QueryGraph does something terrifying to C++ developers… it uses dynamic typing and lookup for resolvers. This might sound inefficient, but actually isn’t that bad due to an optimization that’s been introduced using binding phases.
In QueryGraph, each query type (which hosts nodes) has two relevant declarations, a QuerySpec and a HandlerSpec. The QuerySpec could be viewed as the public interface to the query, consisting of the QuerySpec::input_type as well as the QuerySpec::output_type and finally QuerySpec::query_id. These properties together uniquely identify the query in a way that allows it to be queried. For example, here’s the Fibbonachi node QuerySpec:
struct fibbonachi_query
{
static constexpr auto query_id = "fibbonachi";
using input_type = std::uint64_t;
using output_type = std::uint64_t;
};Resolvers no longer need to know the query spec for all queries that exist, they only need to include query_spec headers for the queries that they can actually perform thanks to a simple map:
std::map< std::type_index, std::any > query_handler_registry;
But, wouldn’t that cause an issue, isn’t that slow? Don’t worry, it doesn’t actually need to do lookups here more than once per query type.
That brings me to the next point about QueryGraph, HandlerSpec. Let me use Fibbonachi as an example:
using fibbonachi_spec = rpnx::query_handler_spec<
fibbonachi_query,
rpnx::typelist< fibbonachi_query >
>;Here we used query_handler_spec with two parameters, the query the handler implements, and a list of dependencies for that query.
When it needs to look up a dependent query handler, it uses this:
template < query_spec_c QuerySpec >auto get_dependency_descriptor() -> query_descriptor< QuerySpec >&{ static_assert(HandlerSpec::dependency_specs::template index_of< QuerySpec >() != static_cast< std::size_t >(-1), "Failed to resolve index of dependency descriptor: QuerySpec is not listed in HandlerSpec::dependency_specs, no entry in dependency_descriptors exists"); constexpr std::size_t index = HandlerSpec::dependency_specs::template index_of< QuerySpec >(); // Descriptor dependencies should be set during the binding stage, which should occur before // any queries are executed return *std::get< index >(dependency_descriptors);}
You may notice that it uses std::get<index> which is a tuple access via fixed address offset offset so the operation has the same efficiency to foo.bar type struct access.
The query_descriptor provides a type-erased interfaced for querying nodes from the descriptor, via std::function (or maybe rpnx::function later, for a sweet 5% performance improvement over libc++, but that’s for another post).
Registration of queries happens in two phases, first each query is registered, one at a time, then query handlers are “bound” by storing pointers to those dependency descriptors in the dependency_descriptors tuple. No more recompiling the whole project, now I’ll only need to recompile the queries that change!
So how do I write these resolvers this time? With coroutines again, although these are a bit more ergonomic (if slightly more verbose sometimes):
rpnx::querygraph::coroutine<fibbonachi_spec> fibbonachi_impl(std::uint64_t n)
{
if (n == 0)
{
co_return 0;
}
else if (n == 1)
{
co_return 1;
}
auto n1 = rpnx::querygraph::query_request<fibbonachi_query>(n - 1);
co_yield rpnx::querygraph::dependency(n1);
co_return co_await fibbonachi_subimpl(n - 2) + co_await n1;
}
That seems easy enough right? You might be wondering why I am using co_yield here. The answer to that is parallelism. The QueryGraph solver uses a multithreaded work-stealing executor framework. Yielding a dependency allows us to schedule it without waiting for the result of the query to complete. We can co_await on a query, which implicitly schedules it if we haven’t already done so, but co_yield allows us to schedule it without waiting on the result, so we can kick the node off and then fetch the result later. In that regard, it’s worth noting that creating a query object does not schedule any work by itself. This is a design limitation of QueryGraph but one that I have considered to be optimal considering the effect of waiting until co_await to schedule the callback in the general case, namely co_await suspends the current coroutine, which means the executor can potentially resume execution of a recently formed query immediately without taking a lock on the scheduling queue. You could consider this to be a form of optimization similar to tail-call recursion, but for coroutine scheduling.
This doesn’t mean that no locks are taken, as the node lookup tables themselves and nodes are locking constructs, but there are many node-locks and table shards and not many executor queues, so the chance of mutex contention on the scheduler queue is much higher than on a node-lock.
It may be noticed that I also co_awaited on something that was not a query, but looked like a normal function call, what was that? It was a cosubroutine. Here’s the implementation of that one:
rpnx::querygraph::coroutine<fibbonachi_spec>::cosubroutine<std::uint64_t> fibbonachi_subimpl(std::uint64_t n){ co_yield rpnx::debug_message("Sumimpl step calculating recursively for n={}", n); if (n == 0) { co_return 0; } else if (n == 1) { co_return 1; } auto sum = co_await fibbonachi_subimpl(n - 1) + co_await rpnx::querygraph::query_request<fibbonachi_query>(n - 2); co_return sum;}
Cosubroutines are a bit like the regular routines, but they are useful for operations that don’t quite fit the model of a query. A query has an input and an output, it may also depend on other queries. What a query doesn’t do is mutate the inputs or transform large values cheaply. Queries are inherently pure functions which are memoized and calculated once. Their outputs are stored and persist in RAM even when they are no longer needed, and while conc_unordered_map is quite fast, acquiring a shard lock isn’t free. Cosubroutines bridge the gap between the query model and traditional procedural programming model, they can mutate their inputs, don’t have cached outputs, and generally provide the same flexibility as ordinary functions.
You may observe here that I can co_yield debug messages, and from the previous screenshot, that this includes the source line and location. It has std::format based semantics, these aren’t limited to cosubroutine, they can also be emitted from the main coroutine if desired.
Cosubroutines can make queries and yield debug_messages just like their parent node, so they provide the flexibility needed to maintain navigable debugging information.
When QueryGraph is done, I expect Quxlang development to re-accelerate at a much higher rate than before.
Speaking of the Quxlang development process, I’ve got a few main things that need to be implemented:
- Placement new and destroy need constructor/destructor via pointer
- Global objects need… something? Still thinking how to do this better than C++ did with the static initialization order issues.
- Union types in constexpr… somehow
- Procedure pointers…
After these main issues are dealt with, I feel like I begin turning my attention to native lowering. Which should be relatively trivial given my prior experience with LLVM, and given the fact that Quxlang IR is already quite low-level.
Exceptions wont be available in the first preview version of Quxlang, exception handling isn’t easy to implement, even with LLVM. This doesn’t mean I hate exceptions, it just means I hate DWARF unwind tables. 🙂
Fun fact, while trying to implement rpnx::function, I already identified another area where Quxlang should be measurably faster than C++ (when it’s released)… in std::function, due to the way C++ binds function parameters vs Quxlang, it should be possible to implement them much more efficiently in Quxlang. That’s because in C++, assigning a std::function with a function value triggers a forced decay into a function pointer, which the dispatch function then calls. I tried my best to get around this, but it’s just not possible in C++. The best I could do is adding an interface like my_function.set_function<free_function>(); instead of my_function = free_function;. In the latter case, it’s actually seemingly impossible to grab the identity of the RHS function rather than a function pointer in C++. The best you can do is get a reference type to the function’s type, and decay that into a function pointer. Oddly, if you use lambda function, the static binding is part of the lambda’s type, so this would make lambdas more efficient than free functions in C++ for use with std::function as they completely elide the issue. I feel as though the fact that function identity is forced to decay into a pointer with no escape hatch is a weakness of the C++ type system; but Quxlang will fix that. 🙂
Oh and I added a bunch of integration with my new-ish csetup/cbuild tools. It’s still optional if you like typing out CMake commands by hand though.

Leave a comment